Nihongo
![]()
Nihongo, multi-language Japanese dictionary primarily developed for mobile devices.
Japanese/English, Japanese/German and Japanese/French dictionaries based on the JMDICT and KANJIDIC2 dictionary files from the Electronic Dictionary Research and Development Group.
- The Japanese/English dictionary contains over 170,000 entries and more than 50,000 examples.
- The Japanese/German dictionary contains over 90,000 entries and more than 13,000 examples.
- The Japanese/French dictionary contains over 15,000 entries and more than 19,000 examples.
Includes Japanese verbs Conjugation, intuitive kanji look-up engine (based on multi-radical selection), and provides a Japanese text parsing utility.
Freely available online at jpn-dict.appspot.com and on the Amazon Appstore for Android.
Browser Compatibility
Second (and current) version (jpn-dict.appspot.com)
It should work on any relatively recent iOS and Android mobile devices. On desktop computers, only Chrome and Safari are currently supported.
First version (1.jpn-dict.appspot.com)
The following table summarises the results of our tests (run between end of 2013 and beginning of 2014). All other browsers that are not mentioned might very well be compatible.
| Browser | Version | Compatibility |
|---|---|---|
| Safari | iOS (version 7) | ✓ |
| Chrome | iOS (version 33.0.1750.14) | ✓ |
| Safari | Mac OS (any recent versions, i.e., > 2013) | ✓ |
| Chrome | Mac OS (any recent versions, i.e., > 2013) | ✓ |
| Firefox | Mac OS (any recent versions, i.e., > 2013) | ✓ |
| Safari | Win 7 (version 5.1.7) | ✓ |
| Chrome | Win 7 (any recent versions, i.e., > 2013) | ✓ |
| Firefox | Win 7 (any recent versions, i.e., > 2013) | ✓ |
| IE | All versions | ✗ |
We have conducted some tests using the Android Emulator, and the application appeared to be fully compatible (we did not observed any anomalies during the simulations).
Currently, there is no version of Internet Explorer (referred to as IE in the table) compatible.
Words Search

Japanese words can be searched by kanji (漢字), hiragana (ひらがな), katakana (カタカナ) or romaji. In Japanese, many words have the same pronunciation; consequently for a given word either in kana or in romaji, several matches might come up. In such a scenario, the returned list is sorted by “relevance”.
In German, the umlaut, i.e., ä, ö and ü, can be either ommitted (i.e., using the base vowel, e.g., a in lieu of ä) or transcribed as ae, oe and ue, respectively; and the ‘sharp s’ (i.e., ß) can be substituted by ss.
In French, the various diacritics, i.e., é, à, è, ù, â, ê, î, ô, û, ë, ï, ü, ÿ and ç, can be ommitted (i.e., using the base character, e.g., e in lieu of é).
In both, German and French, it is important to remain consistent, i.e., to not mix diacritics and possible alternatives in a same word. For example, to look up the German word überprüfen, the words uberprufen or ueberpruefen are adequate inputs. In contrast, überprufen or ueberprufen or überpruefen, for example, should be avoided.
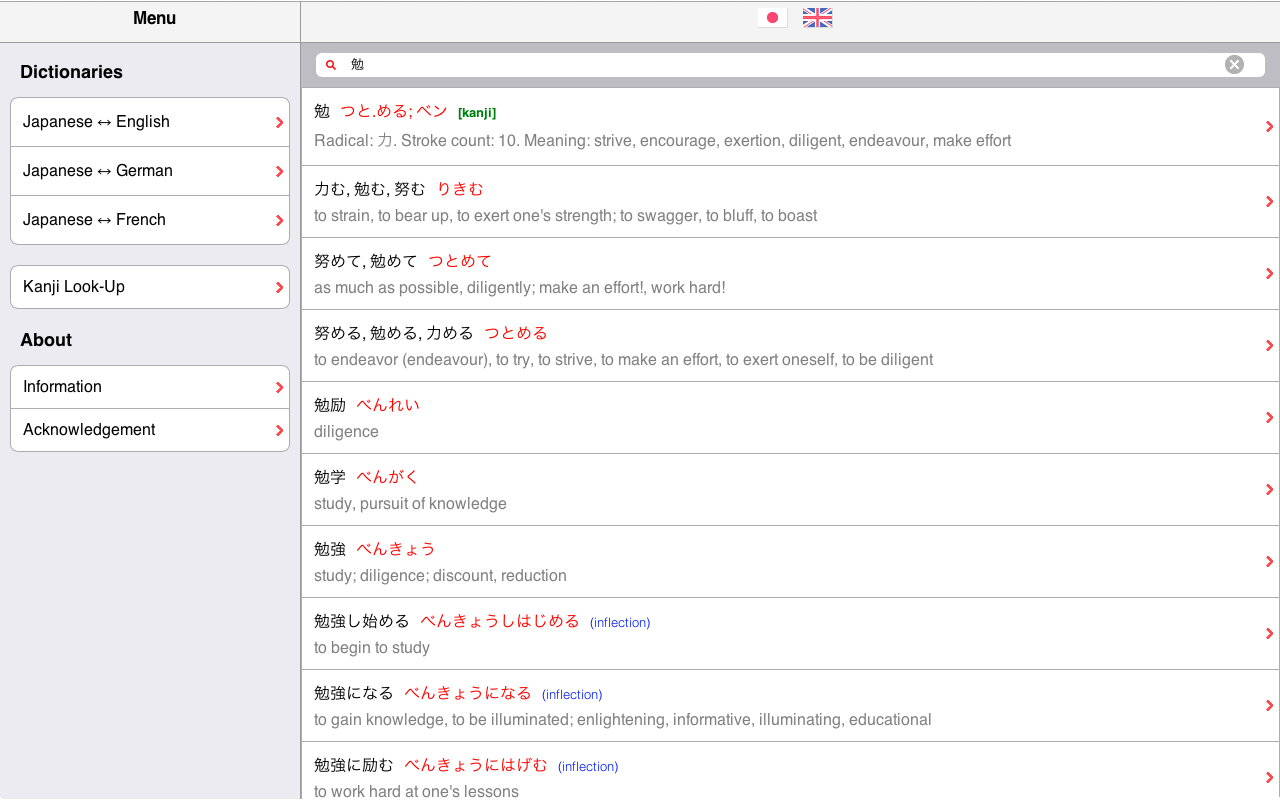
If a single kanji is entered in the search field (and assuming that this kanji is in our database), then the first element of the list of results corresponds to the kanji definition. In such an occurrence, the indication “[Kanji]” appears in green (as illustrated in the left image).
This image shows the indication “(inflection)” for some items in the list of results. It means that the matching entry in the dictionary was not the displayed form, but an inflected form instead. For example, searching for inflected form “食べます” results in the infinitive form, i.e., “食べる”, with the blue indication “(inflection)”.
Words Definition
Each definition consists of at least the reading(s), in both kana and romaji, and the meaning(s). In addition, when applicable, details information about each kanji composing the Japanese entry is provided; and the JLPT level is specified (if relevant). Besides, many definitions are illustrated with various examples.
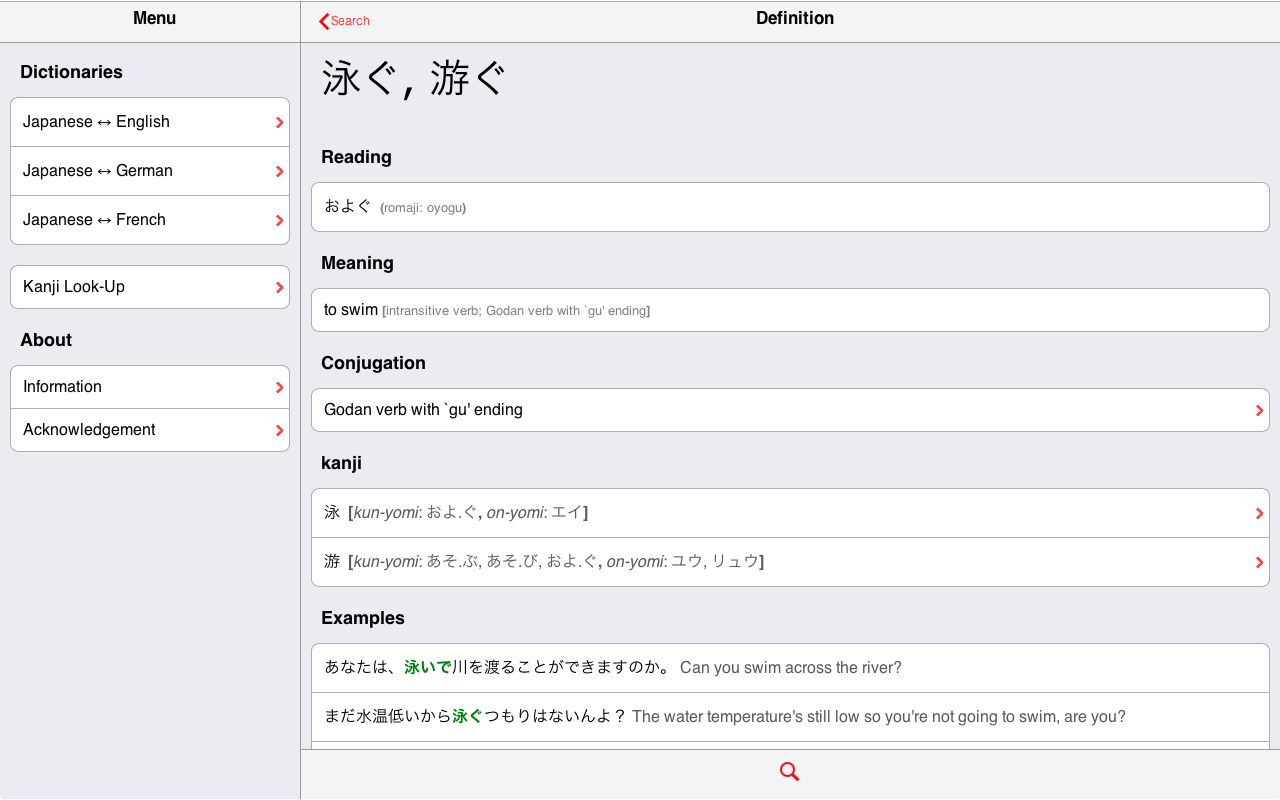
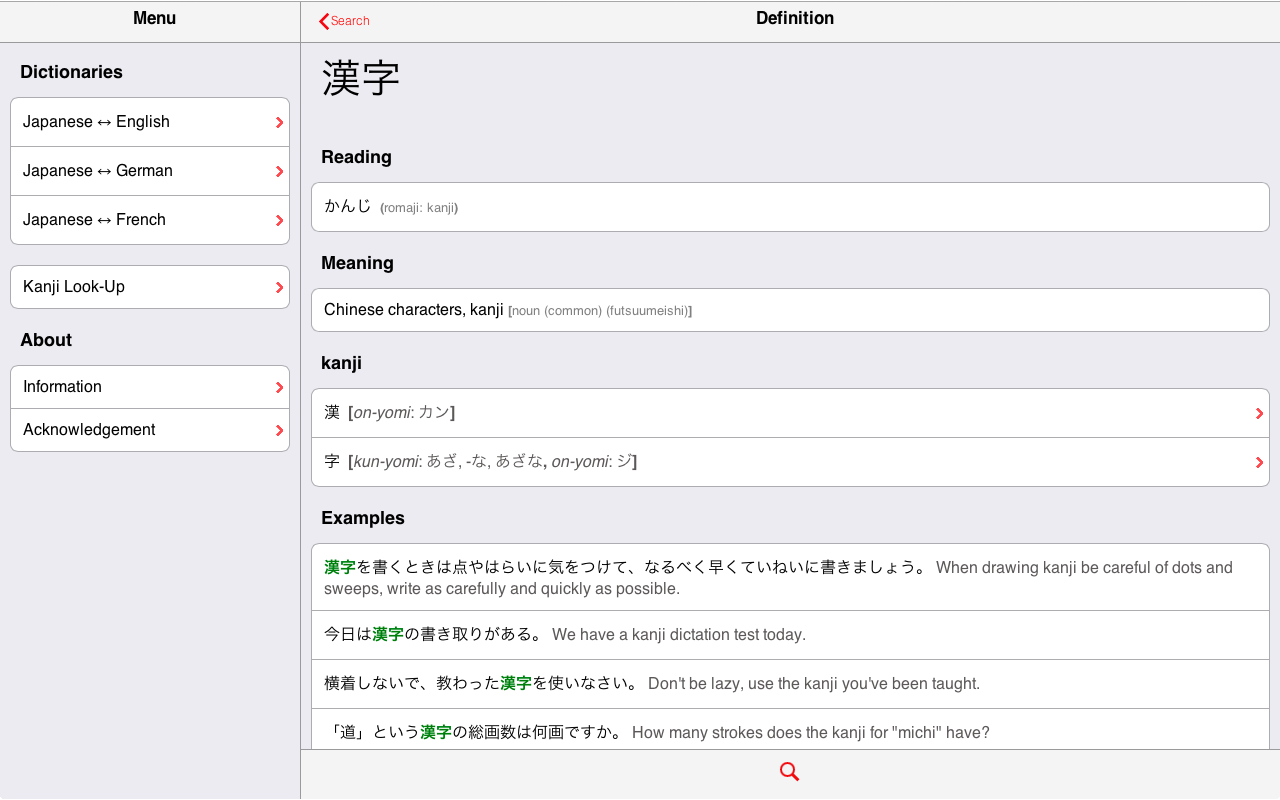
Note: you can access the pages from which the two screenshot have been made: 泳ぐ and 漢字.
Verb Inflections
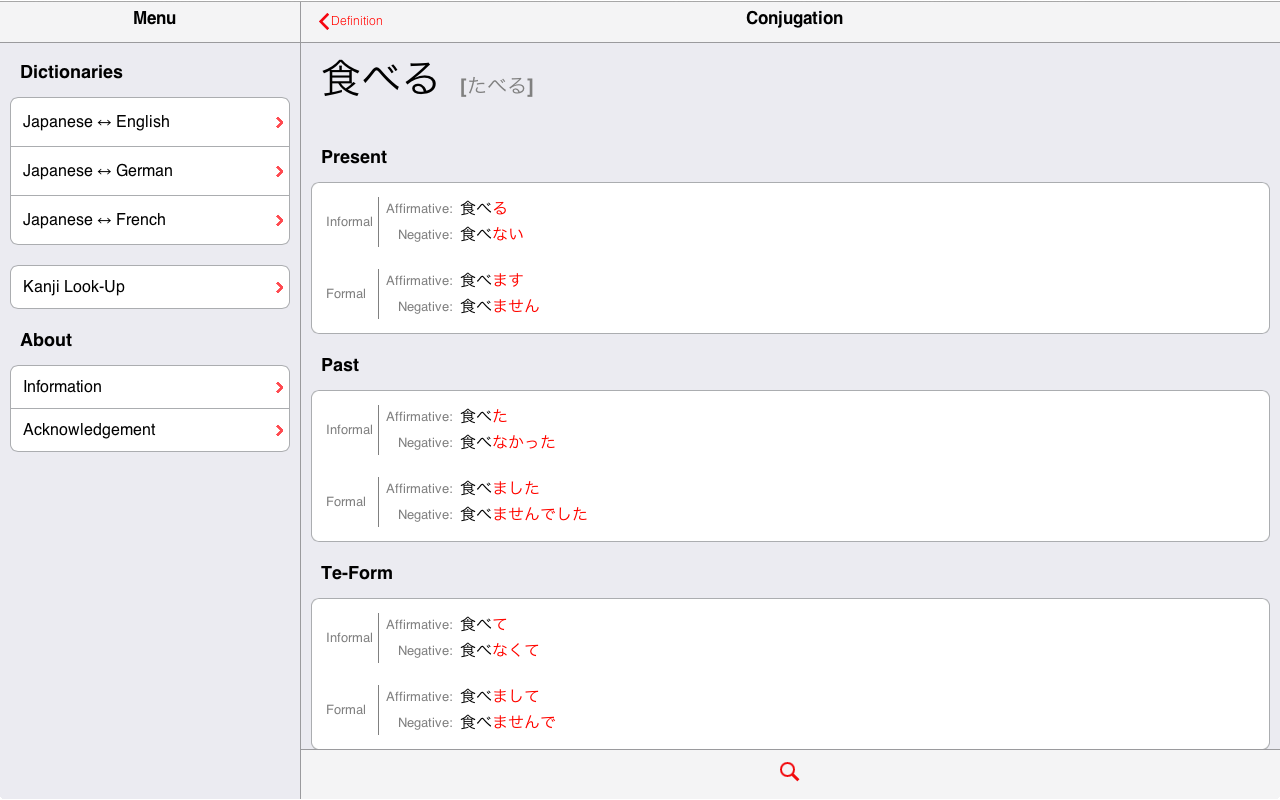

Over 10,500 Japanese conjugated verbs. Each tenses comes in formal and informal forms, and each of those forms comes in affirmative and negative forms.
- present,
- past,
- te-form,
- conditional,
- provisional,
- potential,
- passive,
- causative,
- causative
- passive,
- conjectural,
- alternative,
- imperative and
- volitional.
Note: you can access the pages from which the two screenshot have been made: 食べる and 来る.
Kanji Search
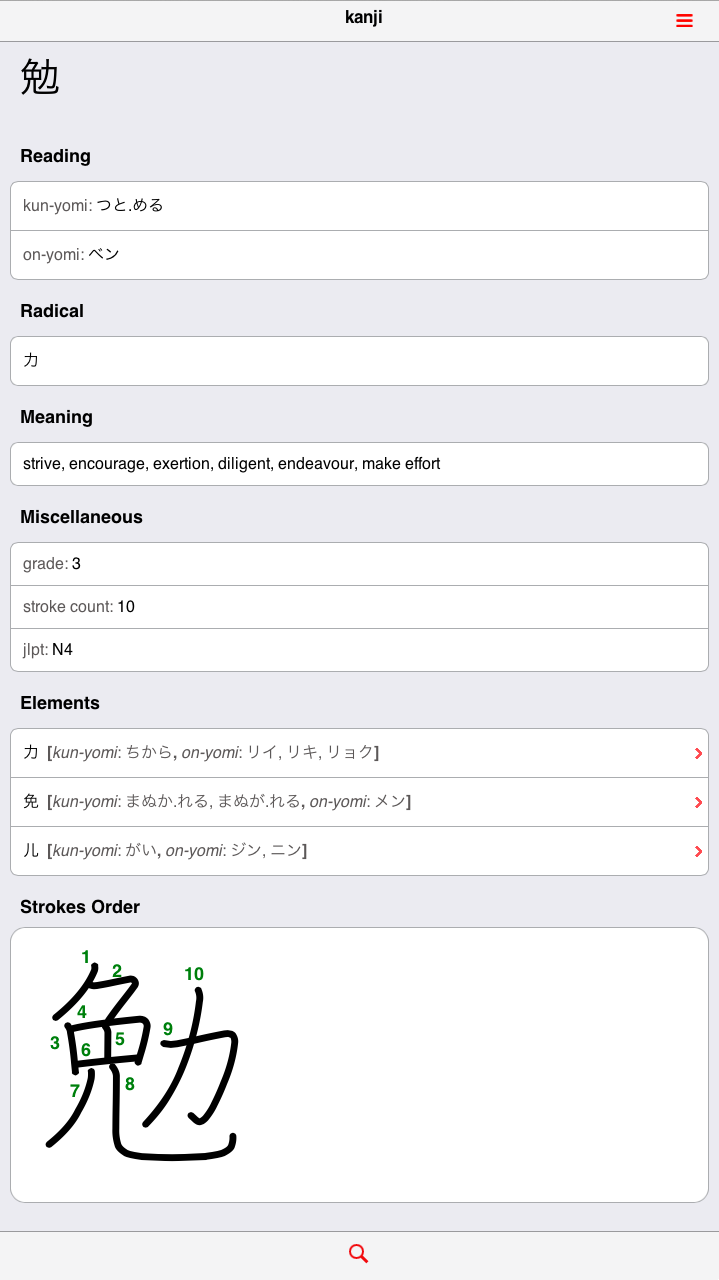
As mentioned above, in the section Word Search, a single kanji can be entered in the search field (either by copy-paste or by using any Japanese input methods). Alternatively, when this approach is out of reach, the kanji look-up engine can be of great help. It is basically a mobile-friendly version of the Jim Breen’s WWWJDIC Multi-Radical Kanji look-up. Further useful information can be found on the Jim Rose’s page dedicated to the kradfile-u license agreement.
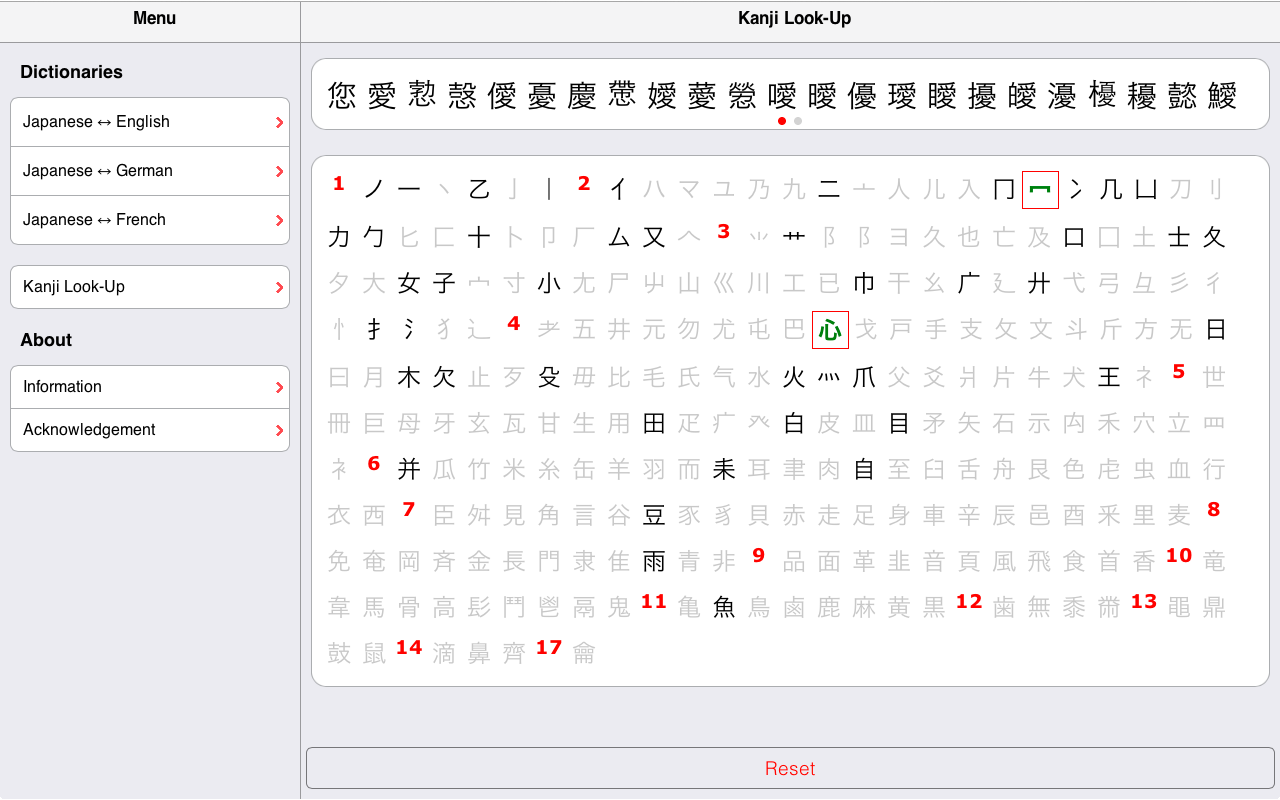
Note: you can access the pages from which the two screenshot have been made: kanji look-up and 勉.
Japanese Text Parsing
Arguably, one of the most useful function of the Jim Breen’s WWWJDIC is the Text Glossing one. We attempted to implement a similar Japanese text parsing function that is (i) mobile-friendly and (ii) multi-language.
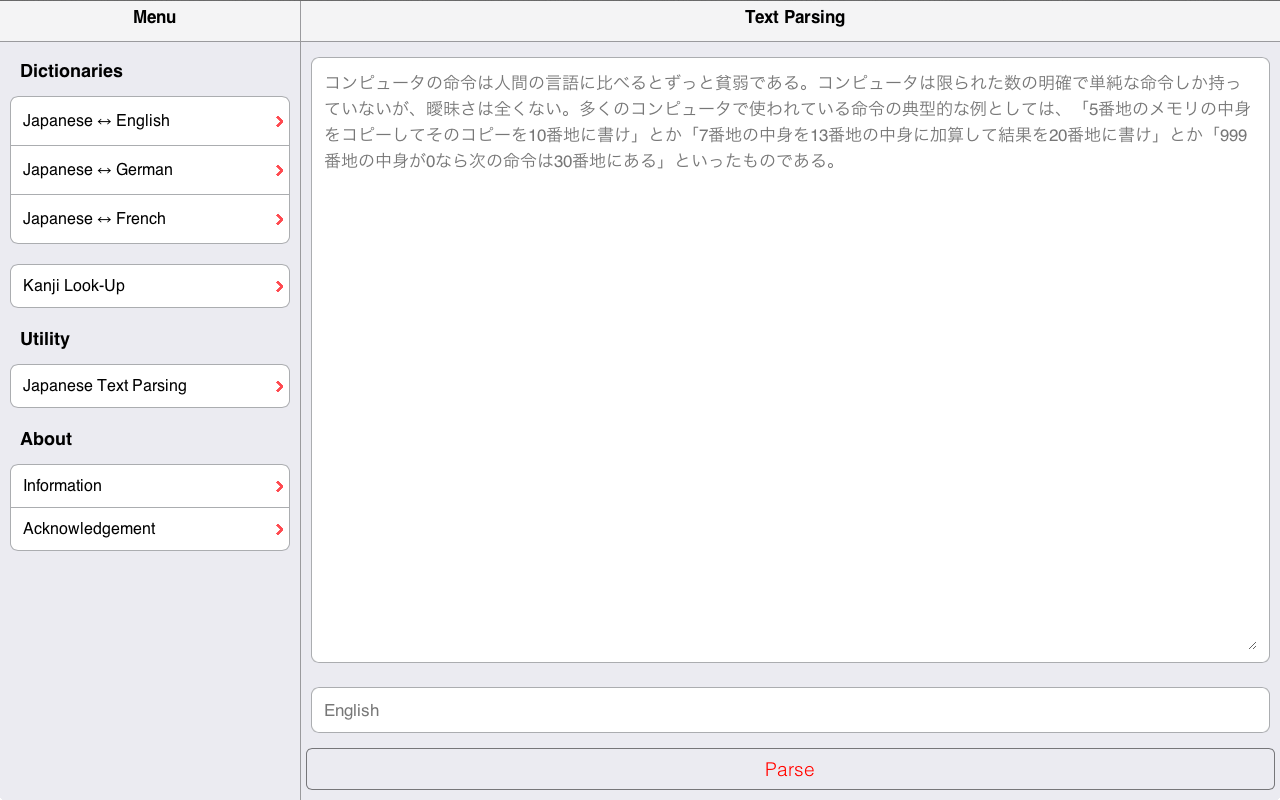
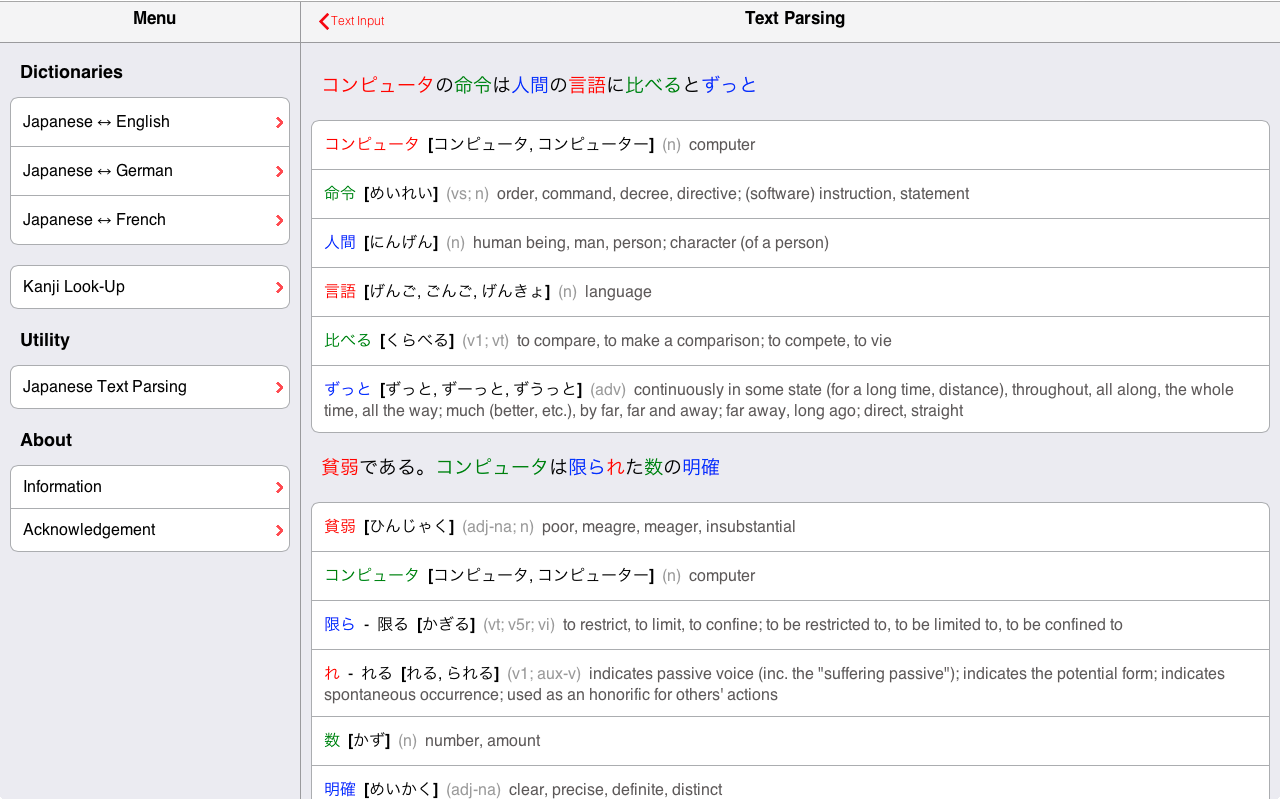
Note: you can access the page from which the result screenshot has been made (left image): text parsing result example.
Some Technical Aspects
This application is developed in Java using GWT and MGWT. It currently runs on (hosted by) Google App Engine. The data are stored using the schemaless NoSQL Google datastore built on top of Bigtable.
The following librairies are used:
This application takes advantage of the HTML5 caching mechanism; approximately 1.5 Mb of data are stored locally within the browser (only the first time the page is loaded). This will subsequently significantly reduce the network activity and greatly improve the performances (e.g., for kanji look-up or for verb inflections).
Chrome users can visualize the status of the cache at: chrome://appcache-internals/
Further Related Readings
Acknowledgement
This application relies on the JMDICT and KANJIDIC2 dictionary files. These files are the property of the Electronic Dictionary Research and Development Group, and are used in conformance with the Group’s licence.
The kradfile-u file is used in accordance with its Licence Agreement.
The KanjiVG is copyright Ulrich Apel and released under the Creative Commons Attribution-Share Alike 3.0 license.
The examples (i.e., the Japanese/English sentence pairs) are from the Tanaka Corpus, and are licenced under the Creative Commons CC-BY.
Disclaimer
This application relies on the JMDICT and KANJIDIC2 dictionary files, and most of the examples are extracted from the “updated file” of the Tanaka Corpus (see the Acknowledment section). Some incorrectnesses and imperfections might remain. We suggest reading this note and this warning.
Regarding the JLPT level, after the JLPT revision in 2010, the “Test Content Specifications” are no longer officially available (see the FAQ of the JLPT official website). Therefore the JLPT level indicated in this application is merely an estimate derived from the specifications of the test prior to the 2010 revision.